【第7回】クラスタリング:k-means、階層的クラスタリング

はじめに
scikit-learnはPythonのオープンソース機械学習ライブラリです。サポートベクターマシン、ランダムフォレスト、k近傍法、などを含む様々な分類、回帰、クラスタリングアルゴリズムを備えており、Pythonの数値計算ライブラリのNumPyとSciPyとやり取りするよう設計されています。
機械学習には正解データがある教師あり学習と正解データがない教師なし学習があります。教師なし学習は正解データがない状態で学習させる手法になっています。教師なし学習にクラスタリングや次元削減があります。クラスタリングは、ある基準を設定してデータ間の類似性を計算し、データをグループ(クラスタ)にまとめることを言います。正解データがないので、どのようなグループになっているかの解釈は分析に委ねられます。クラスタリングには主にk-meansや階層的クラスタリングといった手法があります。
本記事では、scikit-learnを用いてk-meansと階層的クラスタリングの方法を紹介していきます。
1. k-means
k-meansは①各データにランダムに割り当てたクラスタのラベルを用いて、各クラスタのデータの中心をクラスタの中心とし、②各データに対して最も近いクラスタの中心のクラスタに変更し、③再度クラスタの中心を計算して、②、③を繰り返していき、クラスタに変更(またはクラスタの中心に変更)がなくなるまで実施します。
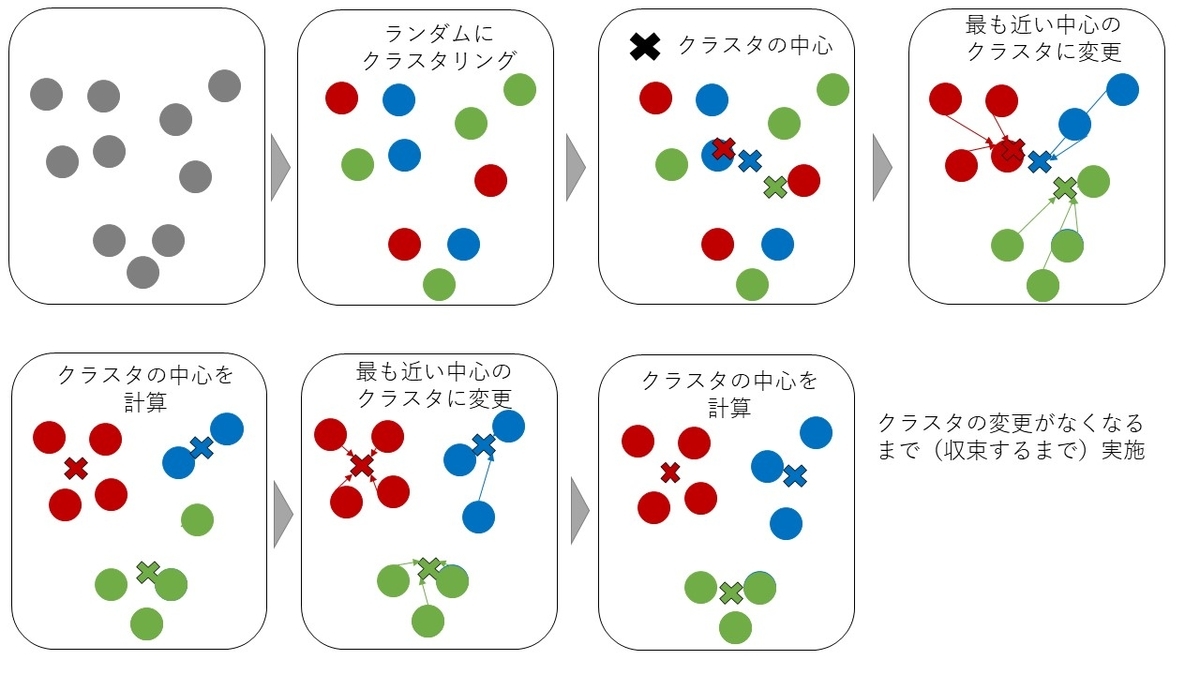
それではコードを見ていきましょう。k-meansではsklearn.cluster.KMeansを使用します。
以下の例では、3種類のワインの学習データセットを用います。今回はその内の説明変数の2つを使用します。KMeansの引数であるn_clustersは形成するクラスターの数、initはクラスターの中心の選択方法を意味しています。
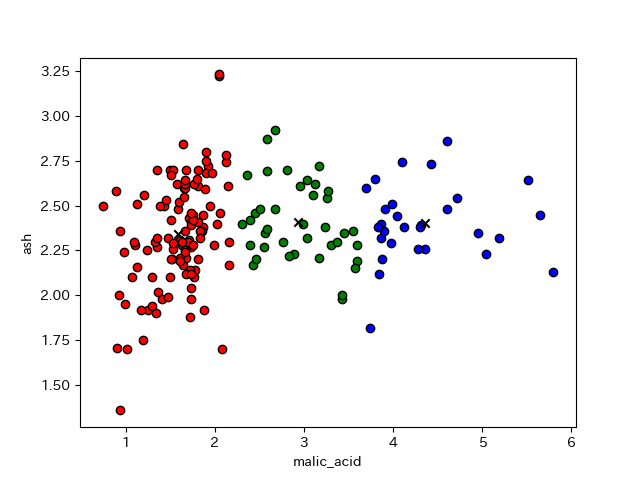
出力結果は以下の様になっています。各データにクラスタ番号が割り振られます。今回は3つのクラスタに分けたので0、1、2の番号になっています。各クラスタ番号をグラフ化すると以下の図の結果となります。なお、×は各クラスタの中心を表しています。
2. 階層的クラスタリング
階層的クラスタリングは大きく分けて凝集型と分割型に分けられます。凝集型はそれぞれのデータを1つのクラスタとし、最も類似するデータを順々にまとめていき、最終的に一つのクラスタになるまで繰り返すクラスタリング手法です。分割型は最初はすべてのデータが1つのクラスタとして扱い、順々にクラスタを分割していくクラスタリング手法です。本記事では凝集型階層的クラスタリングについて紹介していきます。凝集型階層的クラスタリング手法のイメージ図は以下です。
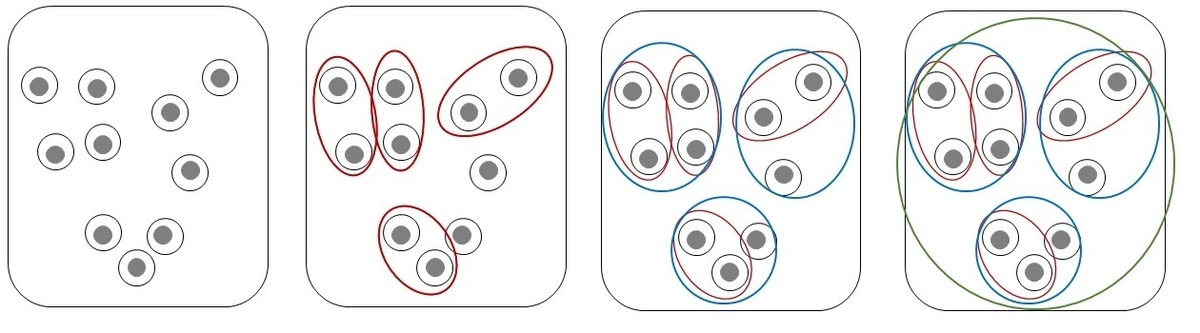
それではコードを確認していきましょう。
凝集型階層的クラスタリングはsklearn.cluster.AgglomerativeClusteringを使用します。以下の例はk-measのコードとほぼ同じでKmeansの代わりに、AgglomerativeClusteringを用いています。AgglomerativeClusteringの引数であるn_clustersは形成するクラスターの数、affinityは「ユークリッド」、「マンハッタン」、「コサイン」などの距離のパラメーター、linkageは観測セット間で使用する距離を意味しています。
出力結果は以下の様になっています。各データにクラスタ番号が割り振られます。今回は3つのクラスタに分けたので0、1、2の番号になっています。各クラスタ番号をグラフ化すると以下の図の結果となります。なお、×は各クラスタの中心を表しています

オススメ書籍
Pythonによるあたらしいデータ分析の教科書
Python3エンジニア認定データ分析試験の教科書にもなっている書籍で、データ分析に必要なPythonの基礎手法を身に付けることができます。具体的には、numpyとpandasを用いたデータの前処理、matplotlibを用いたデータのグラフ化、scikit-learnを用いた機械学習の基礎記述方法を身に付けることができます。これ一つで基礎はバッチリで、実務でも十分活用できると思います。個人的には見やすい書籍でした。
リンク
データサイエンス教本 Pythonで学ぶ統計分析・パターン認識・深層学習・信号処理・時系列データ分析
こちらの書籍は初心者から少し記述できるようになった人、かつ数学的な理論と一緒にPythonの記述方法を理解したい方にオススメです。統計分析、パターン認識、深層学習、信号処理、時系列データといった幅広く実務で使用する手法を学びたい方にもオススメです。
リンク
東京大学のデータサイエンティスト育成講座 ~Pythonで手を動かして学ぶデ―タ分析~
こちらの基礎を抑えながら実務で必要なPython記述法を学べる書籍です。基礎を一つ一つ抑えるというよりも実務で活用できるように必要な知識を身に付けられると感じました。これ一冊あれば十分かなと思いました。
リンク
スキル修得&転職
近年、DXの進展に伴うデジタル人材の需要の高まりに追いついていない状況が続いていると経済産業省がホームページで記載している通り、DX人材、IT人材が不足しているのが現状です。さらにコンピュータの性能向上やAI技術の発展により、よりDX人材、IT人材の需要が高まってきます。さらには、今後の長期間安定して職がある業種とも考えられます。
以下の求人では、IT業界の転職や、IT未経験だけどIT人材を志望する就活を支援してくれます。無料で会員登録もできるので、まずは登録だけでもして様子を見てみてはいかがでしょうか?
▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼
▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲
おわりに
本記事では、scikit-learnを用いてk-meansと階層的クラスタリングの方法を紹介しました。実務経験ではまだ使用したことがりませんが、Python3エンジニア認定データ分析試験で概念などを問われますので、そこはしっかり押さえておきましょう。