【第3回】seleniumを用いた検索ワードに対するWebページのタイトルとURLの取得

はじめに
Webスクレイピングとは、WebサイトからWebページのHTMLデータを取得し、HTMLのテキスト情報を解析することでマーケティングなどの必要な情報やデータを取得して、新たな価値を生むことができます。
Pythonを用いてWebスクレイピングをする際に必要となる代表的なライブラリに、requests、BeautifulSoup、Selniumがあります。Selenium は Web ブラウザの操作を自動化するためのフレームワークです。webスクレイピングでは、HTMLのデータを取得してHTML内の要素を抽出したり、テキストボックスに文字を打込んだり、ページを遷移させたりします。
本記事では、seleniumを用いて検索ワードに対するWebページのタイトルとURLを取得する方法を紹介します。
- はじめに
- 1. 要素の取得方法
- 2. GoogleChromeの起動
- 3. 検索欄に文字を入力
- 4. GoogleChormeで検索実施
- 5. 検索ワードに対するWebページのタイトルとURLの取得
- 6. 応用例
- オススメ書籍
- スキル修得&転職
- おわりに
1. 要素の取得方法
タグ名や属性などのを指定して取得する方法は以下の記事で紹介しています。
2. GoogleChromeの起動
まずはGoogleChormeの起動方法を確認します。Chromeに起動をするためにseleniumのwebdriverを用います。webdriver_managerを用いることでブラウザのバージョンに対応したdriverを取得をしてくれるので、とても便利です。webdriver_managerについては以下の記事でも紹介しています。
以下の例では、GoogleChromeを起動した後にGoogleの検索ページに接続して、そのページをtime.sleep()を用いて10秒間表示しています。
3. 検索欄に文字を入力
先ほど、Googleの検索ページを開いたので、次は検索入力欄に文字を入力します。検索欄に入力するにはsend_keys()を用います。send_keys()を用いることで要素にキーボード入力をすることができます。
それでは入力欄の要素を確認します。GoogleChromeの検索ページを開いて、検索欄内で右クリック→検証を押してみましょう。以下の画像のように表示されます。
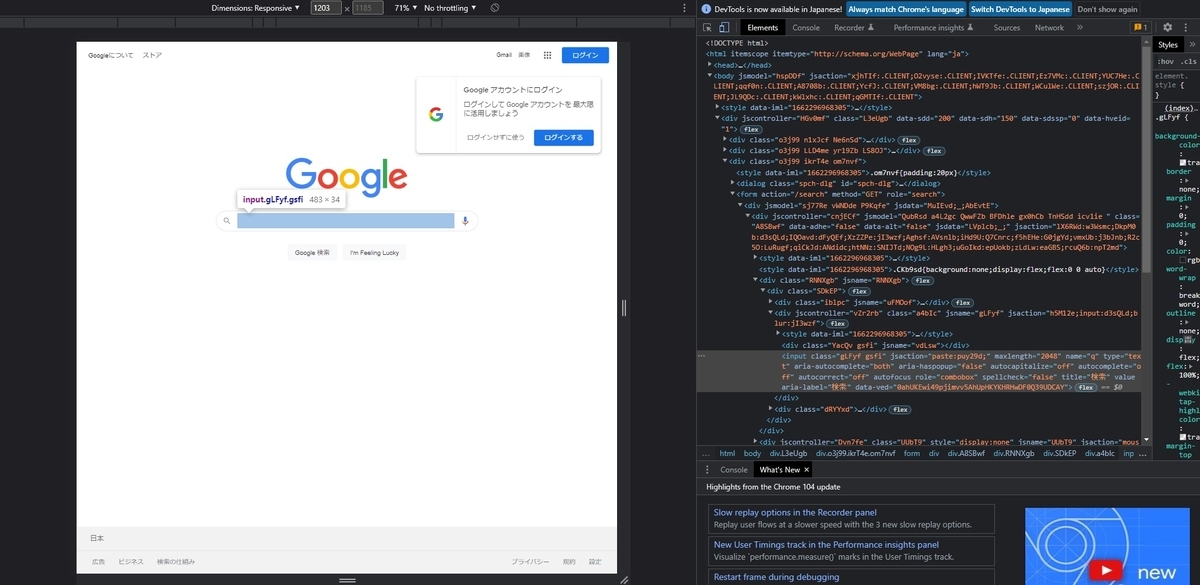
検索欄のコードを確認すると、name属性がqになっているのがわかると思います。

よってname属性がqの要素を取得して、そこでsend_keys()で検索ワードを入力する必要があります。以下の例では入力欄に'selenium'を入力するようにしています。
実行すると以下の様に検索欄にseleniumの文字が入力されたページが10秒間表示されると思います。

4. GoogleChormeで検索実施
GoogleChormeで検索するには、3の内容に加えてエンターキーを押す必要があります。キーボードのボタンを押す操作を行うにはsend_keys(Keys.***)を使用します。***はキーボード名を入れます。Enterキーの場合は、send_keys(Keys.ENTER)となります。検索ワードを入力してエンターキーを押す場合には、send_keys('検索ワード' + Keys.ENTER)となります。以下のコード例を実行すると検索が開始されて検索結果が表示されると思います。
5. 検索ワードに対するWebページのタイトルとURLの取得
それでは検索ワードに対するWebページのタイトルとURLの取得をしていきます。タイトルとURLの取得には、seleniumで要素をタグ名やクラス属性などを指定していきます。
まずはどの要素を取得するか確認していきましょう。検索結果のページでタイトル部分で右クリックをして「検証」を選択します。

HTMLの情報を見ていくと、各ページの単元はclass="g"ごとにまとまっていることがわかりました。よって、find_elements()を用い、クラス名"g"の要素を取得します。(※class名がスペースで区切られていますが、これは複数のclass属性があることを指しています。)
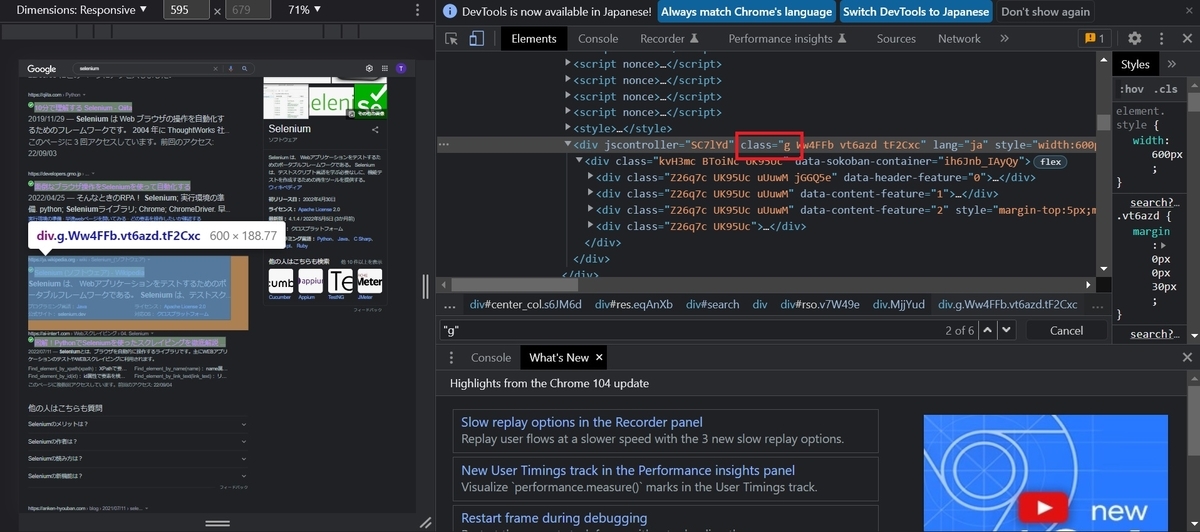
次に、各ページのタイトルとURLがある要素を確認します。HTMLの内容を見るとタイトルはh3タグの要素内に、URLはclass属性"yuRUbf"内のaタグのhref属性内にあることがわかります。このように規則性を確認して要素を取得していく必要があります。
class属性"g"の中にタイトルのあるh3タグの要素、URLのあるclass属性"yuRUbf"内のaタグのhref属性があるので、先にclass属性"g"の要素を取得した後、その要素内から必要な要素を指定して取得します。以下のコード例を実行すると、タイトルのリストとURLのリストを取得することができます。
出力結果は以下の様になります。
上記で得られた結果をエクセルなどで出力するなど活用できます。
6. 応用例
本記事で紹介した手法を用いることで、以下の記事のようにseleniumを用いて検索ワードに対する各ページのタイトルとURLを取得して、そのURLからrequestsとBeautifulSoupを用いてHTMLの取得・解析ができるようになります。
以下の記事では、吉野家の店舗情報の自動取得を題材に、SeleniumによるWebスクレイピングの方法を解説しています。
オススメ書籍
Pythonによるスクレイピング&機械学習開発テクニック増補改訂 Scrapy、BeautifulSoup、scik
リンク
スキル修得&転職
近年、DXの進展に伴うデジタル人材の需要の高まりに追いついていない状況が続いていると経済産業省がホームページで記載している通り、DX人材、IT人材が不足しているのが現状です。さらにコンピュータの性能向上やAI技術の発展により、よりDX人材、IT人材の需要が高まってきます。さらには、今後の長期間安定して職がある業種とも考えられます。
以下の求人では、IT業界の転職や、IT未経験だけどIT人材を志望する就活を支援してくれます。無料で会員登録もできるので、まずは登録だけでもして様子を見てみてはいかがでしょうか?
▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼▼
▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲▲
おわりに
本記事では、seleniumを用いて検索ワードに対するWebページのタイトルとURLを取得する方法を紹介しました。本記事で紹介した手法を用いて拡張することで、より多くの情報を取得できたり、自動化することができます。今回は検索後の最初のページ内の情報しか取得しませんでした。しかし、次のページを押すことも自動化できるので、複数ページの情報を取得することができます。その事例は上記の応用例をご覧ください。